根据《中国算力发展指数白皮书》中的定义,算力是设备通过处理数据,实现特定结果输出的计算能力。

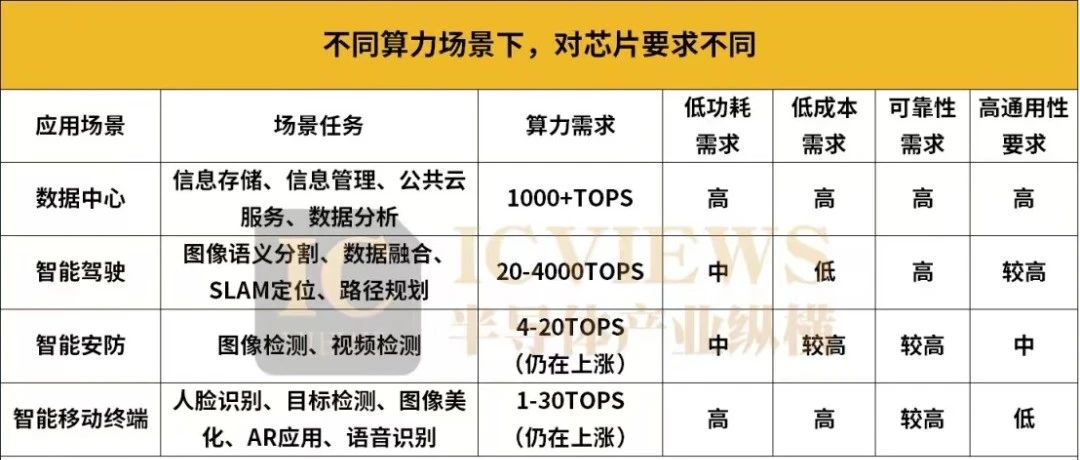
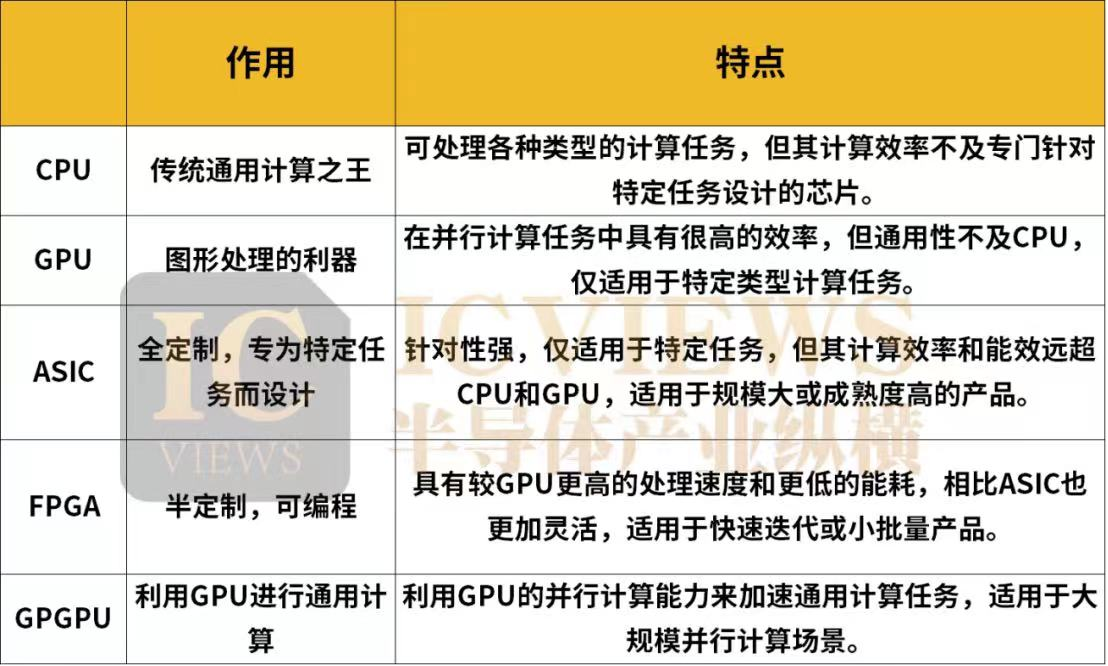
算力实现的核心是CPU、GPU等各类计算芯片,并由计算机、服务器和各类智能终端等承载,海量数据处理和各种数字化应用都离不开算力的加工和计算。那么,不同的算力芯片分别适用于何种应用场景,不同的算力芯片又有哪些区别?小至耳机、手机、PC,大到汽车、互联网、人工智能、数据中心、超级计算机、航天火箭等,“算力”都在其中发挥着核心作用,而不同的算力场景,对芯片的要求也各不同。数据中心作为数字时代的核心基础设施,承载着大量的数据处理、存储和传输任务。因此,它们需要强大的算力来应对各种复杂的计算需求。数据中心和超算需要高于1000TOPS的高算力芯片。当前,超算中心算力已经进入E级算力(百亿亿次运算每秒)时代,并正在向Z(千E)级算力发展。数据中心对于芯片的低功耗、低成本、可靠性以及通用性的要求都极高。智能自动驾驶涉及人机交互、视觉处理、智能决策等众多方面,车载传感器(激光雷达、摄像头、毫米波雷达等)的不断增加,数据处理的实时性、复杂性和准确性要求不断提高,都对车载算力提出了更高的要求。通常,业内认为实现L2级自动辅助驾驶需要的算力在10TOPS以下,L3级需要30~60TOPS,L4级需要超过300TOPS,L5级需要超过1000TOPS,甚至4000+TOPS。所以自动驾驶领域的车载算力是远远大于生活中常见的手机、电脑的计算能力。在智能驾驶中,安全至关重要,因此该场景对算力芯片的可靠性有着极高的要求,对于芯片通用性的要求也较高,对于功耗和成本的要求就相对没有那么苛刻。为了应对当前视频处理、人脸识别以及异常检测等复杂任务的挑战,同时确保系统在未来技术升级和拓展时拥有充足的计算资源。智能安防系统需要大约4-20TOPS的算力,这一数值虽然相较数据中心要小得多,但是也足以保障智能安防系统的高效稳定运作。随着AI安防进入下半场,算力的重要性愈发凸显,这一数值也在不断上涨。智能安防对低成本和可靠性的需求比较高,功耗和通用性的要求则相对中等。在智能移动终端中,可穿戴设备等小型产品对算力的需求相对不高,但智能手机、笔记本电脑等产品对算力的需求正在大幅提升。智能移动终端也是一个对低功耗和低成本有着高要求的应用场景,对可靠性的要求相对较高,对通用性则没有太多的限制。当下的基础算力主要由基于CPU芯片的服务器提供,面向基础通用计算。智能算力主要基于GPU、FPGA、ASIC等芯片的加速计算平台提供,面向人工智能计算。高性能计算算力主要基于融合CPU芯片和GPU芯片打造的计算集群提供,主要面向科学工程计算等应用场景。CPU是传统通用计算之王,包含运算器、控制器、存储器等主要部分。数据在存储器中存储,控制器从存储器中获取数据并交给运算器进行运算,运算完成后再将结果返回存储器。CPU的特点是通用性强,可处理各种类型的计算任务,但其计算效率不及专门针对特定任务设计的芯片。GPU最初用于加速图形渲染,也被称为图形处理的利器。近年来,GPU在深度学习等领域表现出色,被广泛应用于人工智能计算。GPU的特点是具有大量并行计算单元,可同时处理大量数据,使其在并行计算任务中具有很高的效率。但GPU的通用性不及CPU,仅适用于特定类型计算任务。ASIC是一种专为特定任务而设计的芯片。它通过硬件实现算法,可在特定任务中实现极高的计算效率和能效。ASIC的特点是针对性强,仅适用于特定任务,但其计算效率和能效远超CPU和GPU,适用于规模大或成熟度高的产品。FPGA利用门电路直接运算、速度较快。相比于GPU,FPGA具有更高的处理速度和更低的能耗,但相比相同工艺条件下的ASIC,FPGA仍有不及,不过FPGA可以进行编程,相比ASIC也更加灵活。FPGA适用于快速迭代或小批量产品,在AI领域,FPGA芯片可作为加速卡加速AI算法的运算速度。GPGPU即通用图形处理器,其中第一个“GP”通用目的,而第二个“GP”则表示图形处理,主要目标是利用GPU的并行计算能力来加速通用计算任务。可以通俗的将GPGPU理解为一个辅助CPU进行非图形相关程序的运算的工具。适用于大规模并行计算场景,比如科学计算、数据分析、机器学习等场景。
GPU是AI的最优解,但未必是唯一解。
在ChatGPT引发的人工智能热潮下,最受欢迎的莫过于GPU。GPU因何受到AI时代诸多厂商的青睐?原因很简单,因为AI计算和图形计算类似,包含大量的高强度并行计算任务。具体解释为,训练和推理是AI大模型的基石。 在训练环节,通过输入大量的数据,训练出一个复杂的神经网络模型。在推理环节,利用训练好的模型,使用大量数据推理出各种结论。而神经网络的训练和推理过程涉及一系列具体的算法,如矩阵相乘、卷积、循环层处理以及梯度运算等。这些算法通常可以高度并行化,也就是说,它们可以被分解为大量可以同时执行的小任务。而GPU拥有大量的并行处理单元,可以快速地执行深度学习中需要的矩阵运算,从而加速模型的训练和推理。目前,大部分企业的AI训练,采用的都是GPU集群。如果进行合理优化,一块GPU卡,可以提供相当于数十台甚至上百台CPU服务器的算力。这时候可能会有人发问,在AI盛行的当下,单凭GPU就足够了吗?GPU是否会独占未来AI市场的鳌头,成为无可争议的宠儿?非也。GPU固然是当下的最优解,但未必是唯一解。
GPU虽然目前在AI领域占据了主导地位,但是它也面临着一些挑战和局限。比如说,GPU的供应链问题导致了价格上涨和供应不足,这对于AI开发者和用户来说都是一个负担。而CPU则有着更多的竞争者和合作伙伴,可以促进技术的进步和降低成本。而且,CPU也有着更多的优化技术和创新方向,可以让CPU在AI领域发挥出更大的作用。
一些更为精简或小巧的模型,在传统CPU上同样能够展现出卓越的运行效率,而且往往更加经济实惠、节能环保。这证明了在选择硬件时,需根据具体应用场景和模型复杂度来权衡不同处理器的优势。除了运行超大规模的语言模型,CPU还可以运行更小更高效的语言模型。这些语言模型通过一些创新的技术,可以大幅减少计算量和内存占用,从而适应CPU的特点。这也意味着CPU在AI领域并没有被完全边缘化,而是有着不容忽视的优势和潜力。
不仅如此,由于AI加速服务器异构的特点,市场上除了CPU+GPU的组合方式之外,还有其它多种多样的架构,例如:CPU+FPGA、CPU+ASIC、CPU+多种加速卡。技术的变革是迅速的,未来确有可能出现更加高效、更加适合AI计算的新技术。CPU+FPGA、CPU+ASIC便是未来的可能之一。CPU擅长逻辑控制和串行处理,而FPGA则具有并行处理能力和硬件加速特性。通过结合两者,可以显著提升系统的整体性能,特别是在处理复杂任务和大规模数据时。FPGA的可编程性使得其可以根据具体应用场景进行灵活配置和定制。这意味着CPU+FPGA架构可以适应各种不同的需求,从通用计算到特定应用的加速,都可以通过调整FPGA的配置来实现。而ASIC是专门为特定应用设计的集成电路,因此它在性能和功耗上通常都经过了高度优化。与CPU结合使用时,可以确保系统在处理特定任务时具有出色的性能和效率。此外,ASIC的设计是固定的,一旦制造完成,其功能就不会改变。这使得ASIC在需要长时间稳定运行和高可靠性的场景中表现出色。
 上海市智能制造产业协会
上海市智能制造产业协会 上海市集成电路行业协会
上海市集成电路行业协会 华东理工大学
华东理工大学